I am a computer vision algorithm engineer work at Juphoon System Software. Previously, I graduated from Cornell University with a master’s degree in Electrical Engineering. Even before that, I was an undergraduate student at Purdue University.
My research focuses on computer vision and the intersection of vision and other fields (language and sound). In particular, I aim to leverage these to better understand complex human activities through multiple senses. I am also interested in video understanding, human activity recognition, and video enhancement.
Besides research, I enjoy photography, cooking, and fitness.
Please find my CV here
Selected Projects
1. Real-time Communication with Virtual Background
[Doc] [Web Demo] [Real-time Virtual Background Video Demo] [Real-time Blur Background Video Demo]
I demonstrated a model to replace the background in real-time video communication by tackling portrait matting on mobile devices. The proposed model solves issues of previous models and achieves real-time inference speed while maintaining high visual performance. The Virtual background feature can attain over 25 FPS on 720P on iPhone11 in real-time video communication.
I’ve uploaded two video demos for real-time background editing using the proposed model.
Note: Model was trained with public datasets in doc. We are working on a more stable result in the RTC scenario.

2. Real-time Face Detection and Facial Landmark
[Doc] [Video Demo]
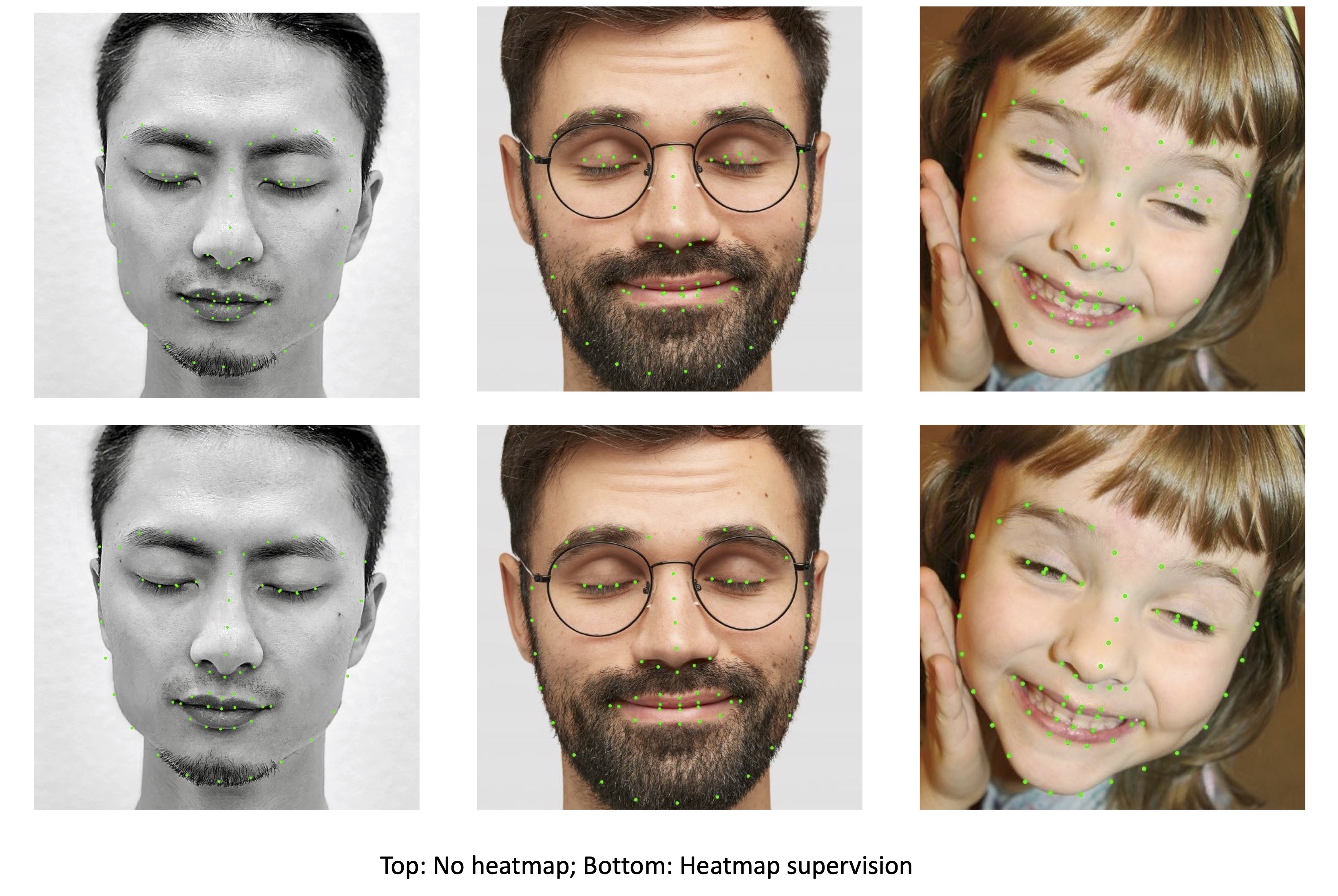
Face detectors and facial landmarks are fundamental to other advanced tasks, such as face recognition, liveness detection, and face editing. In this project, I will demonstrate how to integrate the two open-source works to build a high-performance facial landmark detector, the improvements, and modifications I’ve made for each piece. The integrated model can achieve over 24FPS on iPhone X.

The proposed facial landmark detector uses regression supervision. While detectors trained with regression supervision are generally accurate in most cases, they may expose problems with insufficient robustness in some special cases, such as blinking or opening the mouth, which are essential for facial expression recognition. To address this issue, I use heatmap-assisted supervision, which makes greater use of local information and supervises the learning of each individual keypoint. [Video Demo]